CQL - Continuous Query Language
In today’s data driven economy, organizations depend heavily on data analytics to stay competitive. Advances in Big Data related technologies transformed how organizations interact with data and as a result more and more data is generated at ever increasing rates. And most of these data is available as continuous streams and organizations utilizes stream processing technologies to extract insights in real-time (or as data arrives). As a result of this change in how we collect and process data stream processing platforms like Apache Storm, Spark Streaming and Apache Samza were created based on about a decade of experience using Big Data processing technologies such as Hadoop.
But these modern platforms lack support for SQL like declarative query languages and require sound knowledge on imperative style programming and distributed systems to effectively utilize them. But for broader adoption, support for SQL like continuous query languages or SQL with streaming extensions is required. In this post I’m going to discuss one such language known as CQL for querying data streams invented roughly 10 years ago. Theoretical framework and SQL extensions discussed in CQL paper is still important and we are using concepts from CQL as a foundation for Apache Samza’s Streaming SQL implementation.
What is CQL? #
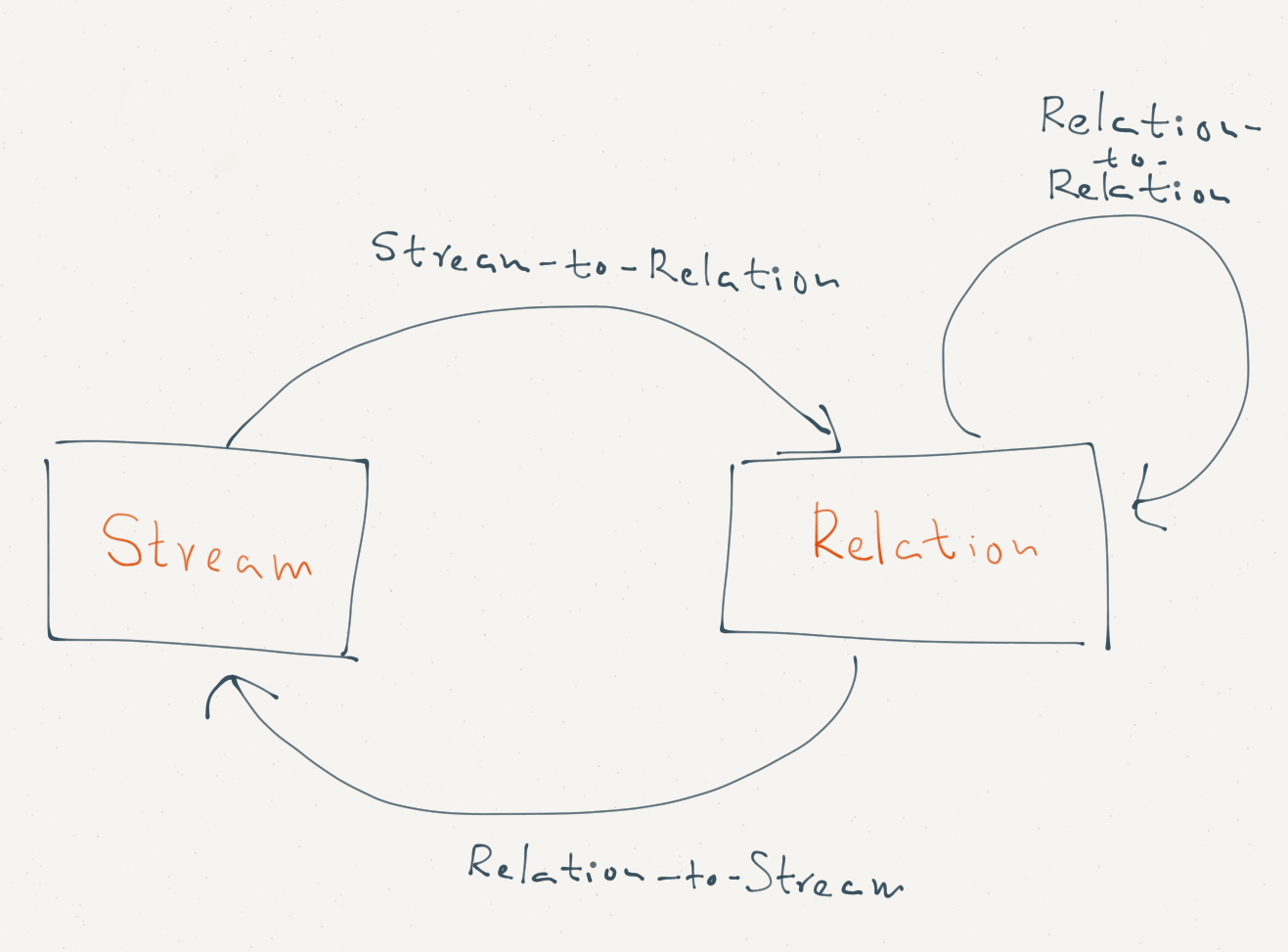
CQL is not SQL, but a SQL based declarative language for querying streaming and stored relations (a.k.a. database tables). Abstract semantics of CQL relies on three types of operations – stream-to-relations, relation-to-relation and relation-to-stream – on two types of data – streams and relations.
Streams and relations #
- Stream - (possibly infinite) bag of elements , where s is a tuple and t is the timestamp of the element
- Relation - time instant to finite but unbounded bag of tuples mapping. This is different from general definition of relation where there is no notion of time and relations in the context of CQL is know as instantaneous relations which varies with the time.
Operators #
- Stream-to-relation - produces a (instantaneous) relation from a stream. Window operator (there are different types such as sliding and tumbling) is the only stream-to-relation operator available in CQL.
- Relation-to-relation - produces a relation from one or more relations. Selection, projection and aggregation operators in CQL are relaiton-to-relation operators.
- Relation-to-stream - produces a stream from a relation. Difference between previous and current instantaneous relation is used to convert a relation to a stream.
Stream-to-stream operators are absent and they should be constructed by combining three types of operators defined above. Below figure from CQL paper is the best visualization of abstract semantics defined in CQL.
Why CQL is interesting? #
Operators like join and some aggregation operators available in SQL are blocking and impossible to evaluate over streams. So, a window operator which divide the stream into possibly overlapping subsets is used after stream scan to reduce the scope of the query to a window extent.
In CQL, the concept of window is embedded into the semantics using the concept instantaneous relation and this allows query execution engines to implement operators such as joins and aggregations as they are operating on general relations. In addition to that, CQL allows integration of stored relations to streaming queries without any magic because once a stream is converted to an instantaneous relation, we are basically working on relations.
In addition to above mentioned semantic features, query execution strategy explained in CQL is also interesting.
CQL Query Execution #
Streams and Insert/Delete Streams #
In CQL runtime stream is represented as a sequence of timestamped insert tuples. And time-varying relation (bag of tuples) is represented as timestamped insert and delete tuples. These insertions and deletions represent the changing state of a relation. This technique makes easy to implement incremental processing of streams.
Synopses are used to maintain the intermediate state such as current contents of a sliding window or current state of a relation for join operation.
More information about CQL query execution can be found in Section 12 of CQL paper.
Limitations #
Coming soon.